While existing social networking services tend to connect people who know each other, people show a desire to also connect to yet unknown people in physical proximity. Existing research shows that people tend to connect to similar people. Utilizing technology in order to stimulate human interaction between strangers, we consider the scenario of two strangers meeting. On the example of similarity in musical taste, we develop a solution for the problem of similarity estimation in proximity-based mobile social networks. We show that a single exchange of a probabilistic data structure between two devices can closely estimate the similarity of two users – without the need to contact a third-party server. We introduce metrics for fast and space-efficient approximation of the Dice coefficient of two multisets – based on the comparison of two Counting Bloom Filters or two Count-Min Sketches. Our analysis shows that utilizing a single hash function minimizes the error when comparing these probabilistic data structures. The size that should be chosen for the data structure depends on the expected average number of unique input elements. Using real user data, we show that a Counting Bloom Filter with a single hash function and a length of 128 is sufficient to accurately estimate the similarity between two multisets representing the musical tastes of two users. Our approach is generalizable for any other similarity estimation of frequencies represented as multisets.
I presented this work as a paper at IEEE Trustcom 2018. You can find the full paper here (PDF).
We use a Counting Bloom Filter (CBF):
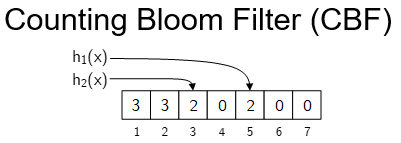
We define CBF-Dice(P,Q) as a similarity-metric for two CBFs P and Q:

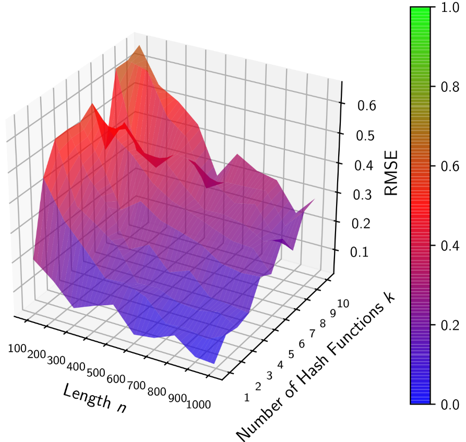
Experimental results with the million song dataset show us that a CBF with a single hash function performs best (details see paper):
We implemented the exchange of CBFs in our TYDR prototype. By touching two phones running the modified TYDR version, NFC is used to exchange CBFs. Then, CBF-Dice is used for similarity estimation. The results are shown to the user:
