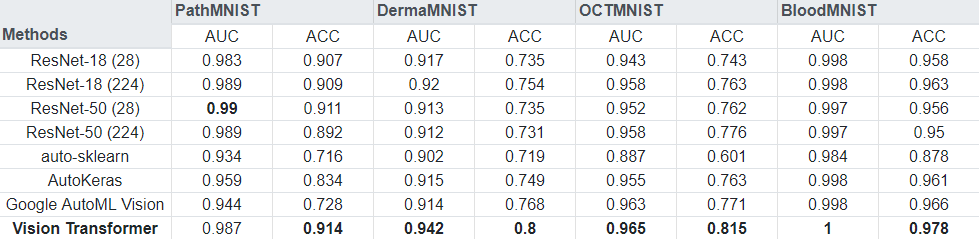
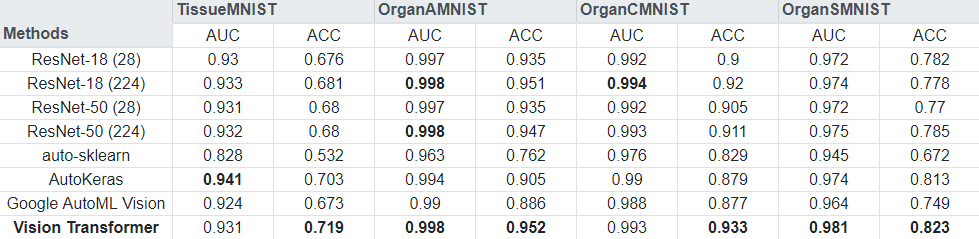
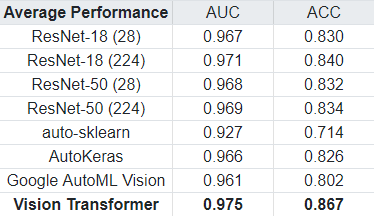
Vision Transformers can outperform other methods like RNNs in classification tasks in the medical domain. MedMNIST (v2) is a collection of biomedical images, and contains eight 2D image datasets for a multi-class classification task. Using a pre-trained Vision Transformer model, and fine-tuning it for each dataset, we were able to outperform almost all of the baselines presented by the authors of the dataset collection, see below. The full code for the experiment is available on GitHub.