Ecological momentary assessments (EMAs) prompt users with a short questionnaire. One of the biggest challenges in such studies is the lack of adherence, i.e., users stop filling out the questionnaires. Being able to predict if a user will fill out a questionnaire could allow for specifically addressing those users, or for over-sampling populations at higher risk of dropping out of a study.
Based on an observational study of the general population, we analyzed data from almost 1,000 users. The data include a large variety of sensor data from the users’ smartphones. With machine learning, we predict adherence on a day-to-day level, as well as predict adherence based on participant data after on-boarding.
Results:
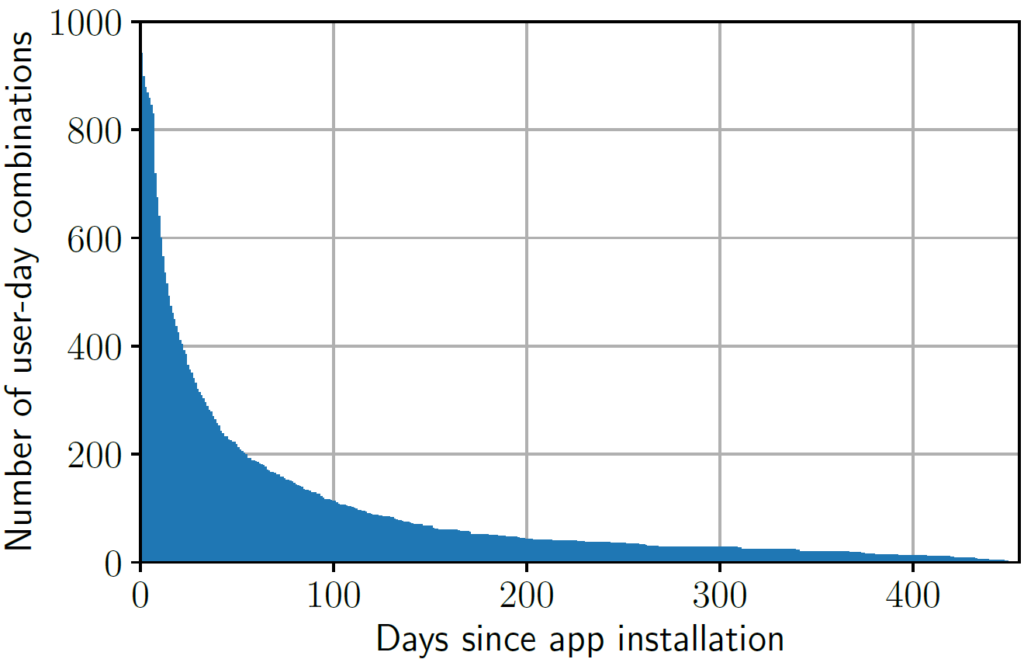
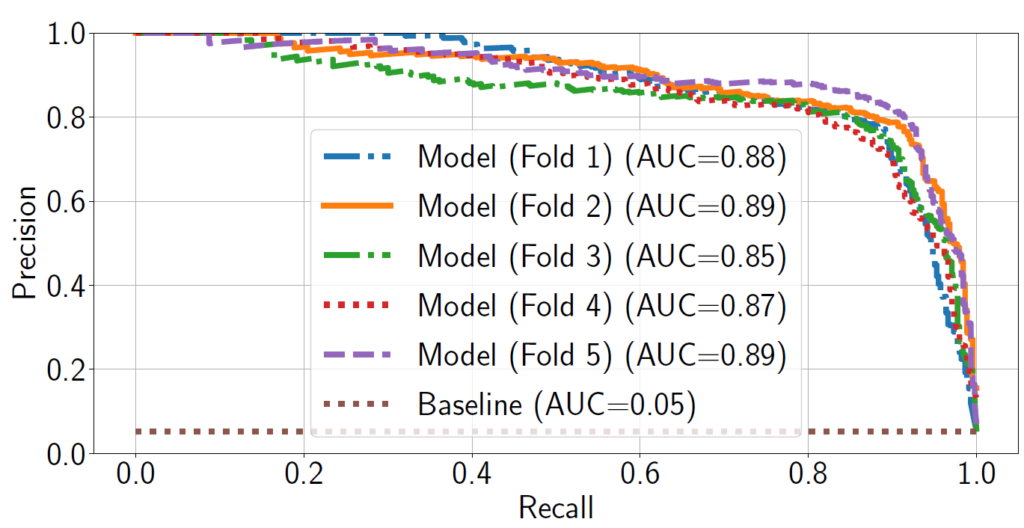
- For day-to-day prediction, the best performing model was a model based on metadata features (days since first questionnaire was filled out, days since the last questionnaire was filled out, number of filled-out questionnaires, days since app installation), yielding an area under the precision-recall curve of 0.89.
- The inclusion of sensor data did not improve the model’s performance, indicating that the high cost of collecting and processing sensor data is not worth the benefits for predicting fill-out behavior.
- Predicting at sign-up if a user will adhere to a questionnaire prompt at least once was better than chance, but further studies are needed.
You can find our full article published in Expert Systems with Applications (IF: 7.5) here (full PDF here).